STRF gradmaps: 2D-CNN on CRCNS AA2 (OV / conspecific)
![]()
This notebook fits the 2D-CNN of Pennington & David (2023) on a slice of the CRCNS AA2 auditory dataset (zebra finch ovoidalis, OV — a thalamic nucleus relaying auditory information to forebrain Field L) and extracts a per-neuron STRF gradient map from the trained model — the canonical interpretable “what does this cell respond to?” figure for nonlinear receptive-field models.
The 2D-CNN doesn’t have an explicit STRF parameter to plot. Instead, we ask: at the neuron’s last-timestep prediction, what change in a null spectrogram (zeros) most increases the response? Autodiff gives that gradient in closed form — a (F, T) map per neuron. The deepSTRF base class implements this in AudioEncodingModel.STRF_gradmap(); the batch dimension parallelises the calculation across all N output neurons in a single forward / backward pass.
Scope: 59 OV cells × 20 conspecific stimuli at dt_ms=5. 100% valid (s, n) coverage on this subset, so no NaN-aware bookkeeping is exercised here — the same notebook on the full 494-cell, 117- stim AA2 would be the next step (see “What’s next”).
Setup — Google Colab
If you’re running on Google Colab, the cell below installs deepSTRF from source. Local installs (pip install -e .) are no-ops.
Note on data: AA2 is an authenticated CRCNS dataset. To auto-download it, set $CRCNS_USERNAME and $CRCNS_PASSWORD (free account at https://crcns.org/). On a local machine that already has the data extracted, it’s picked up from the cache automatically.
[1]:
import sys
if 'google.colab' in sys.modules:
!pip install -q git+https://github.com/urancon/deepSTRF.git
print("deepSTRF installed from GitHub.")
else:
print("Local environment — assuming deepSTRF is already importable.")
Local environment — assuming deepSTRF is already importable.
Imports
[2]:
%matplotlib inline
import time
import matplotlib.pyplot as plt
import numpy as np
import torch
from torch.utils.data import DataLoader, Subset
from deepSTRF.datasets.audio.crcns_aa2 import CRCNSAA2Dataset
from deepSTRF.models.audio import ConvNet2D
from deepSTRF.training import Fitter, set_random_seed
from deepSTRF.utils import neural_collate, plot_strf_grid
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
Using device: cuda
1. Load CRCNS AA2 — OV cells, conspecific stimuli only
We narrow the dataset at construction time via the areas= and stimuli= arguments. A separate notebook covers the select_*_by_attr runtime filtering API and the bidirectional rule from data_paradigm.md §8; here we just want a clean small subset to showcase gradmaps.
[3]:
ds = CRCNSAA2Dataset(download=True, dt_ms=5, areas=('OV',), stimuli=('conspecific',))
print(f"OV + conspecific: N={ds.N_neurons} cells, S={len(ds.stims)} stims, "
f"F={ds.F} bands, dt={ds.dt} ms")
T_min = min(s.shape[-1] for s in ds.stims)
T_max = max(s.shape[-1] for s in ds.stims)
print(f"stim T range: {T_min}..{T_max} frames "
f"({T_min*ds.dt/1000:.2f} s .. {T_max*ds.dt/1000:.2f} s)")
valid_frac = ds.nrn_masks.float().mean().item()
print(f"valid (s, n) pairs: {100*valid_frac:.1f}%")
OV + conspecific: N=59 cells, S=20 stims, F=32 bands, dt=5 ms
stim T range: 234..511 frames (1.17 s .. 2.56 s)
valid (s, n) pairs: 100.0%
2. Train / val / test split + per-band standardisation
14 / 3 / 3 split, all conspecific. Standardisation statistics are computed on train+val and applied to all stimuli — the held-out test set is transformed with the same mean and std.
[4]:
set_random_seed(0)
S = len(ds)
g = torch.Generator().manual_seed(0)
perm = torch.randperm(S, generator=g).tolist()
train_idx = perm[:14]
val_idx = perm[14:17]
test_idx = perm[17:20]
print(f"split: train {len(train_idx)} | val {len(val_idx)} | test {len(test_idx)}")
stats = ds.standardize_stims(stim_indices=train_idx + val_idx, per_band=True)
print(f"per-band mean range: [{stats['mean'].min():.3f}, {stats['mean'].max():.3f}]")
print(f"per-band std range: [{stats['std'].min():.3f}, {stats['std'].max():.3f}]")
split: train 14 | val 3 | test 3
per-band mean range: [0.007, 1.557]
per-band std range: [0.001, 1.433]
3. Build the 2D-CNN and fit
ConvNet2D is the deepSTRF port of Pennington & David’s 2D-CNN: three (Conv2d → CausalLayerNorm → LeakyReLU) blocks over the spectrogram, then a 2-layer FC reading out the population. Default temporal_window_size = 3·(K_T − 1) = 24 frames (120 ms at our 5 ms resolution) sets the gradmap window we’ll plot in section 5.
Hyperparameters:
batch_size=4— with only 14 train stims, larger batches collapse to gradient descent (≤ 1 step per epoch) and lose SGD noise. On a bigger AA2 subset (more stims) you can dial this up, on this particular GPU up to ~32.patience=50on val cc_norm — the demo set is tiny so each epoch is quick and we can afford a long patience.track_train_metrics=False— skip the per-epoch recomputation of cc / cc_norm on the training accumulator; not useful at this scale and saves a few seconds per epoch.
[5]:
N = ds.N_neurons
train_loader = DataLoader(Subset(ds, train_idx), batch_size=1,
shuffle=True, collate_fn=neural_collate)
val_loader = DataLoader(Subset(ds, val_idx), batch_size=1,
shuffle=False, collate_fn=neural_collate)
test_loader = DataLoader(Subset(ds, test_idx), batch_size=1,
shuffle=False, collate_fn=neural_collate)
set_random_seed(0)
model = ConvNet2D(
n_frequency_bands=ds.F, kernel_size=(3, 9),
c_hidden=10, n_hidden=20, out_neurons=N,
)
print(f"ConvNet2D params: {model.count_trainable_params():,}, "
f"gradmap window: T={model.T} frames ({model.T * ds.dt} ms)")
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3, weight_decay=0.0)
fitter = Fitter(
model, train_loader, val_loader,
optimizer=optimizer, device=device,
max_epochs=2000, patience=50,
monitor="val_cc_norm", mode="max",
track_train_metrics=False,
# default log_fn prints per-epoch lines
)
t0 = time.time()
history = fitter.fit()
elapsed = time.time() - t0
print(f"\nfit completed: {len(history)} epochs in {elapsed/60:.1f} min")
ConvNet2D params: 12,401, gradmap window: T=24 frames (120 ms)
epoch 0 | train_loss=0.0554 | val_loss=0.0456 | val_cc=0.0113 | val_cc_norm=0.0055
epoch 1 | train_loss=0.0450 | val_loss=0.0388 | val_cc=0.0360 | val_cc_norm=0.0248
epoch 2 | train_loss=0.0385 | val_loss=0.0352 | val_cc=0.0702 | val_cc_norm=0.0615
epoch 3 | train_loss=0.0351 | val_loss=0.0329 | val_cc=0.1782 | val_cc_norm=0.1957
epoch 4 | train_loss=0.0328 | val_loss=0.0314 | val_cc=0.2422 | val_cc_norm=0.2773
epoch 5 | train_loss=0.0314 | val_loss=0.0303 | val_cc=0.2746 | val_cc_norm=0.3216
epoch 6 | train_loss=0.0299 | val_loss=0.0288 | val_cc=0.3145 | val_cc_norm=0.3786
epoch 7 | train_loss=0.0286 | val_loss=0.0280 | val_cc=0.3576 | val_cc_norm=0.4388
epoch 8 | train_loss=0.0278 | val_loss=0.0276 | val_cc=0.3767 | val_cc_norm=0.4663
epoch 9 | train_loss=0.0273 | val_loss=0.0270 | val_cc=0.3874 | val_cc_norm=0.4808
epoch 10 | train_loss=0.0271 | val_loss=0.0274 | val_cc=0.3989 | val_cc_norm=0.4969
epoch 11 | train_loss=0.0269 | val_loss=0.0269 | val_cc=0.4001 | val_cc_norm=0.5006
epoch 12 | train_loss=0.0268 | val_loss=0.0262 | val_cc=0.4083 | val_cc_norm=0.5127
epoch 13 | train_loss=0.0264 | val_loss=0.0258 | val_cc=0.4225 | val_cc_norm=0.5291
epoch 14 | train_loss=0.0264 | val_loss=0.0257 | val_cc=0.4285 | val_cc_norm=0.5398
epoch 15 | train_loss=0.0255 | val_loss=0.0253 | val_cc=0.4345 | val_cc_norm=0.5471
epoch 16 | train_loss=0.0251 | val_loss=0.0248 | val_cc=0.4418 | val_cc_norm=0.5560
epoch 17 | train_loss=0.0247 | val_loss=0.0252 | val_cc=0.4480 | val_cc_norm=0.5643
epoch 18 | train_loss=0.0245 | val_loss=0.0247 | val_cc=0.4579 | val_cc_norm=0.5766
epoch 19 | train_loss=0.0245 | val_loss=0.0242 | val_cc=0.4589 | val_cc_norm=0.5792
epoch 20 | train_loss=0.0243 | val_loss=0.0240 | val_cc=0.4653 | val_cc_norm=0.5872
epoch 21 | train_loss=0.0239 | val_loss=0.0249 | val_cc=0.4637 | val_cc_norm=0.5853
epoch 22 | train_loss=0.0235 | val_loss=0.0235 | val_cc=0.4756 | val_cc_norm=0.6003
epoch 23 | train_loss=0.0236 | val_loss=0.0247 | val_cc=0.4789 | val_cc_norm=0.6048
epoch 24 | train_loss=0.0234 | val_loss=0.0238 | val_cc=0.4794 | val_cc_norm=0.6061
epoch 25 | train_loss=0.0231 | val_loss=0.0240 | val_cc=0.4835 | val_cc_norm=0.6111
epoch 26 | train_loss=0.0231 | val_loss=0.0252 | val_cc=0.4706 | val_cc_norm=0.5954
epoch 27 | train_loss=0.0233 | val_loss=0.0246 | val_cc=0.4768 | val_cc_norm=0.6035
epoch 28 | train_loss=0.0231 | val_loss=0.0240 | val_cc=0.4882 | val_cc_norm=0.6179
epoch 29 | train_loss=0.0228 | val_loss=0.0233 | val_cc=0.4898 | val_cc_norm=0.6204
epoch 30 | train_loss=0.0225 | val_loss=0.0244 | val_cc=0.4885 | val_cc_norm=0.6191
epoch 31 | train_loss=0.0223 | val_loss=0.0235 | val_cc=0.4887 | val_cc_norm=0.6197
epoch 32 | train_loss=0.0225 | val_loss=0.0233 | val_cc=0.4909 | val_cc_norm=0.6230
epoch 33 | train_loss=0.0222 | val_loss=0.0230 | val_cc=0.4942 | val_cc_norm=0.6272
epoch 34 | train_loss=0.0219 | val_loss=0.0234 | val_cc=0.4888 | val_cc_norm=0.6206
epoch 35 | train_loss=0.0221 | val_loss=0.0234 | val_cc=0.4882 | val_cc_norm=0.6206
epoch 36 | train_loss=0.0220 | val_loss=0.0231 | val_cc=0.4929 | val_cc_norm=0.6270
epoch 37 | train_loss=0.0217 | val_loss=0.0231 | val_cc=0.4993 | val_cc_norm=0.6340
epoch 38 | train_loss=0.0216 | val_loss=0.0229 | val_cc=0.5045 | val_cc_norm=0.6422
epoch 39 | train_loss=0.0215 | val_loss=0.0232 | val_cc=0.4990 | val_cc_norm=0.6357
epoch 40 | train_loss=0.0213 | val_loss=0.0224 | val_cc=0.5076 | val_cc_norm=0.6465
epoch 41 | train_loss=0.0213 | val_loss=0.0221 | val_cc=0.5104 | val_cc_norm=0.6505
epoch 42 | train_loss=0.0211 | val_loss=0.0222 | val_cc=0.5133 | val_cc_norm=0.6543
epoch 43 | train_loss=0.0212 | val_loss=0.0226 | val_cc=0.5038 | val_cc_norm=0.6425
epoch 44 | train_loss=0.0208 | val_loss=0.0228 | val_cc=0.5093 | val_cc_norm=0.6499
epoch 45 | train_loss=0.0208 | val_loss=0.0239 | val_cc=0.5044 | val_cc_norm=0.6431
epoch 46 | train_loss=0.0211 | val_loss=0.0225 | val_cc=0.5121 | val_cc_norm=0.6528
epoch 47 | train_loss=0.0210 | val_loss=0.0220 | val_cc=0.5161 | val_cc_norm=0.6585
epoch 48 | train_loss=0.0209 | val_loss=0.0232 | val_cc=0.5103 | val_cc_norm=0.6509
epoch 49 | train_loss=0.0205 | val_loss=0.0222 | val_cc=0.5137 | val_cc_norm=0.6553
epoch 50 | train_loss=0.0207 | val_loss=0.0231 | val_cc=0.5099 | val_cc_norm=0.6503
epoch 51 | train_loss=0.0203 | val_loss=0.0225 | val_cc=0.5163 | val_cc_norm=0.6593
epoch 52 | train_loss=0.0203 | val_loss=0.0219 | val_cc=0.5173 | val_cc_norm=0.6607
epoch 53 | train_loss=0.0201 | val_loss=0.0222 | val_cc=0.5179 | val_cc_norm=0.6615
epoch 54 | train_loss=0.0200 | val_loss=0.0218 | val_cc=0.5195 | val_cc_norm=0.6635
epoch 55 | train_loss=0.0198 | val_loss=0.0231 | val_cc=0.5113 | val_cc_norm=0.6529
epoch 56 | train_loss=0.0198 | val_loss=0.0219 | val_cc=0.5205 | val_cc_norm=0.6650
epoch 57 | train_loss=0.0199 | val_loss=0.0224 | val_cc=0.5208 | val_cc_norm=0.6655
epoch 58 | train_loss=0.0198 | val_loss=0.0221 | val_cc=0.5236 | val_cc_norm=0.6693
epoch 59 | train_loss=0.0197 | val_loss=0.0217 | val_cc=0.5209 | val_cc_norm=0.6661
epoch 60 | train_loss=0.0198 | val_loss=0.0219 | val_cc=0.5186 | val_cc_norm=0.6628
epoch 61 | train_loss=0.0198 | val_loss=0.0219 | val_cc=0.5222 | val_cc_norm=0.6678
epoch 62 | train_loss=0.0196 | val_loss=0.0231 | val_cc=0.5086 | val_cc_norm=0.6500
epoch 63 | train_loss=0.0196 | val_loss=0.0223 | val_cc=0.5221 | val_cc_norm=0.6670
epoch 64 | train_loss=0.0195 | val_loss=0.0216 | val_cc=0.5263 | val_cc_norm=0.6730
epoch 65 | train_loss=0.0193 | val_loss=0.0218 | val_cc=0.5245 | val_cc_norm=0.6709
epoch 66 | train_loss=0.0194 | val_loss=0.0225 | val_cc=0.5199 | val_cc_norm=0.6647
epoch 67 | train_loss=0.0194 | val_loss=0.0226 | val_cc=0.5181 | val_cc_norm=0.6625
epoch 68 | train_loss=0.0192 | val_loss=0.0223 | val_cc=0.5268 | val_cc_norm=0.6735
epoch 69 | train_loss=0.0191 | val_loss=0.0220 | val_cc=0.5247 | val_cc_norm=0.6711
epoch 70 | train_loss=0.0189 | val_loss=0.0225 | val_cc=0.5242 | val_cc_norm=0.6706
epoch 71 | train_loss=0.0188 | val_loss=0.0223 | val_cc=0.5169 | val_cc_norm=0.6608
epoch 72 | train_loss=0.0188 | val_loss=0.0217 | val_cc=0.5240 | val_cc_norm=0.6702
epoch 73 | train_loss=0.0188 | val_loss=0.0222 | val_cc=0.5252 | val_cc_norm=0.6714
epoch 74 | train_loss=0.0185 | val_loss=0.0227 | val_cc=0.5195 | val_cc_norm=0.6641
epoch 75 | train_loss=0.0185 | val_loss=0.0220 | val_cc=0.5242 | val_cc_norm=0.6701
epoch 76 | train_loss=0.0184 | val_loss=0.0224 | val_cc=0.5198 | val_cc_norm=0.6643
epoch 77 | train_loss=0.0183 | val_loss=0.0218 | val_cc=0.5263 | val_cc_norm=0.6731
epoch 78 | train_loss=0.0183 | val_loss=0.0224 | val_cc=0.5164 | val_cc_norm=0.6599
epoch 79 | train_loss=0.0182 | val_loss=0.0221 | val_cc=0.5209 | val_cc_norm=0.6658
epoch 80 | train_loss=0.0183 | val_loss=0.0234 | val_cc=0.5122 | val_cc_norm=0.6545
epoch 81 | train_loss=0.0182 | val_loss=0.0216 | val_cc=0.5288 | val_cc_norm=0.6766
epoch 82 | train_loss=0.0181 | val_loss=0.0220 | val_cc=0.5198 | val_cc_norm=0.6645
epoch 83 | train_loss=0.0182 | val_loss=0.0220 | val_cc=0.5241 | val_cc_norm=0.6703
epoch 84 | train_loss=0.0180 | val_loss=0.0225 | val_cc=0.5182 | val_cc_norm=0.6625
epoch 85 | train_loss=0.0180 | val_loss=0.0219 | val_cc=0.5263 | val_cc_norm=0.6733
epoch 86 | train_loss=0.0179 | val_loss=0.0222 | val_cc=0.5186 | val_cc_norm=0.6633
epoch 87 | train_loss=0.0179 | val_loss=0.0218 | val_cc=0.5239 | val_cc_norm=0.6701
epoch 88 | train_loss=0.0178 | val_loss=0.0225 | val_cc=0.5215 | val_cc_norm=0.6664
epoch 89 | train_loss=0.0177 | val_loss=0.0227 | val_cc=0.5176 | val_cc_norm=0.6622
epoch 90 | train_loss=0.0178 | val_loss=0.0224 | val_cc=0.5188 | val_cc_norm=0.6635
epoch 91 | train_loss=0.0176 | val_loss=0.0227 | val_cc=0.5179 | val_cc_norm=0.6622
epoch 92 | train_loss=0.0175 | val_loss=0.0220 | val_cc=0.5217 | val_cc_norm=0.6672
epoch 93 | train_loss=0.0175 | val_loss=0.0228 | val_cc=0.5224 | val_cc_norm=0.6683
epoch 94 | train_loss=0.0175 | val_loss=0.0228 | val_cc=0.5158 | val_cc_norm=0.6594
epoch 95 | train_loss=0.0173 | val_loss=0.0221 | val_cc=0.5232 | val_cc_norm=0.6694
epoch 96 | train_loss=0.0173 | val_loss=0.0223 | val_cc=0.5193 | val_cc_norm=0.6643
epoch 97 | train_loss=0.0173 | val_loss=0.0224 | val_cc=0.5180 | val_cc_norm=0.6628
epoch 98 | train_loss=0.0172 | val_loss=0.0228 | val_cc=0.5176 | val_cc_norm=0.6616
epoch 99 | train_loss=0.0173 | val_loss=0.0220 | val_cc=0.5239 | val_cc_norm=0.6702
epoch 100 | train_loss=0.0172 | val_loss=0.0223 | val_cc=0.5184 | val_cc_norm=0.6633
epoch 101 | train_loss=0.0172 | val_loss=0.0229 | val_cc=0.5195 | val_cc_norm=0.6642
epoch 102 | train_loss=0.0171 | val_loss=0.0227 | val_cc=0.5163 | val_cc_norm=0.6603
epoch 103 | train_loss=0.0171 | val_loss=0.0224 | val_cc=0.5181 | val_cc_norm=0.6628
epoch 104 | train_loss=0.0170 | val_loss=0.0223 | val_cc=0.5165 | val_cc_norm=0.6605
epoch 105 | train_loss=0.0171 | val_loss=0.0229 | val_cc=0.5151 | val_cc_norm=0.6582
epoch 106 | train_loss=0.0169 | val_loss=0.0225 | val_cc=0.5195 | val_cc_norm=0.6644
epoch 107 | train_loss=0.0169 | val_loss=0.0221 | val_cc=0.5199 | val_cc_norm=0.6651
epoch 108 | train_loss=0.0169 | val_loss=0.0231 | val_cc=0.5175 | val_cc_norm=0.6620
epoch 109 | train_loss=0.0169 | val_loss=0.0231 | val_cc=0.5116 | val_cc_norm=0.6543
epoch 110 | train_loss=0.0171 | val_loss=0.0225 | val_cc=0.5161 | val_cc_norm=0.6604
epoch 111 | train_loss=0.0170 | val_loss=0.0232 | val_cc=0.5139 | val_cc_norm=0.6574
epoch 112 | train_loss=0.0168 | val_loss=0.0225 | val_cc=0.5193 | val_cc_norm=0.6644
epoch 113 | train_loss=0.0167 | val_loss=0.0223 | val_cc=0.5220 | val_cc_norm=0.6679
epoch 114 | train_loss=0.0166 | val_loss=0.0227 | val_cc=0.5168 | val_cc_norm=0.6609
epoch 115 | train_loss=0.0167 | val_loss=0.0225 | val_cc=0.5204 | val_cc_norm=0.6659
epoch 116 | train_loss=0.0166 | val_loss=0.0222 | val_cc=0.5256 | val_cc_norm=0.6727
epoch 117 | train_loss=0.0166 | val_loss=0.0231 | val_cc=0.5200 | val_cc_norm=0.6653
epoch 118 | train_loss=0.0165 | val_loss=0.0226 | val_cc=0.5158 | val_cc_norm=0.6595
epoch 119 | train_loss=0.0165 | val_loss=0.0229 | val_cc=0.5165 | val_cc_norm=0.6607
epoch 120 | train_loss=0.0166 | val_loss=0.0228 | val_cc=0.5185 | val_cc_norm=0.6631
epoch 121 | train_loss=0.0165 | val_loss=0.0223 | val_cc=0.5216 | val_cc_norm=0.6675
epoch 122 | train_loss=0.0165 | val_loss=0.0232 | val_cc=0.5208 | val_cc_norm=0.6667
epoch 123 | train_loss=0.0164 | val_loss=0.0229 | val_cc=0.5192 | val_cc_norm=0.6641
epoch 124 | train_loss=0.0163 | val_loss=0.0225 | val_cc=0.5250 | val_cc_norm=0.6720
epoch 125 | train_loss=0.0164 | val_loss=0.0238 | val_cc=0.5144 | val_cc_norm=0.6582
epoch 126 | train_loss=0.0165 | val_loss=0.0231 | val_cc=0.5100 | val_cc_norm=0.6519
epoch 127 | train_loss=0.0165 | val_loss=0.0226 | val_cc=0.5192 | val_cc_norm=0.6642
epoch 128 | train_loss=0.0164 | val_loss=0.0230 | val_cc=0.5174 | val_cc_norm=0.6618
epoch 129 | train_loss=0.0162 | val_loss=0.0230 | val_cc=0.5169 | val_cc_norm=0.6613
epoch 130 | train_loss=0.0161 | val_loss=0.0226 | val_cc=0.5217 | val_cc_norm=0.6681
epoch 131 | train_loss=0.0161 | val_loss=0.0230 | val_cc=0.5150 | val_cc_norm=0.6587
fit completed: 132 epochs in 0.7 min
4. Test-set summary
[6]:
test = fitter.evaluate(test_loader)
test_cc_norm = test["cc_norm"].cpu()
test_cc = test["cc"].cpu()
print(f"test cc: {torch.nanmean(test_cc):+.3f}")
print(f"test cc_norm: {torch.nanmean(test_cc_norm):+.3f}")
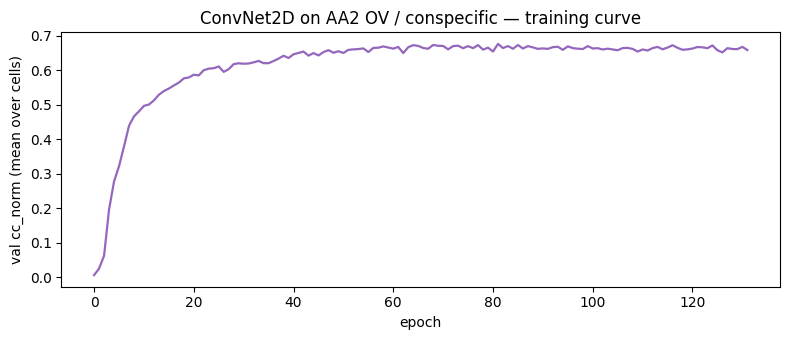
# Training curve
fig, ax = plt.subplots(figsize=(8, 3.5))
ep = [h["epoch"] for h in history]
vC = [torch.nanmean(h["val_cc_norm"]).item() for h in history]
ax.plot(ep, vC, lw=1.6, color='tab:purple')
ax.set_xlabel("epoch"); ax.set_ylabel("val cc_norm (mean over cells)")
ax.set_title("ConvNet2D on AA2 OV / conspecific — training curve")
plt.tight_layout(); plt.show()
test cc: +0.497
test cc_norm: +0.653
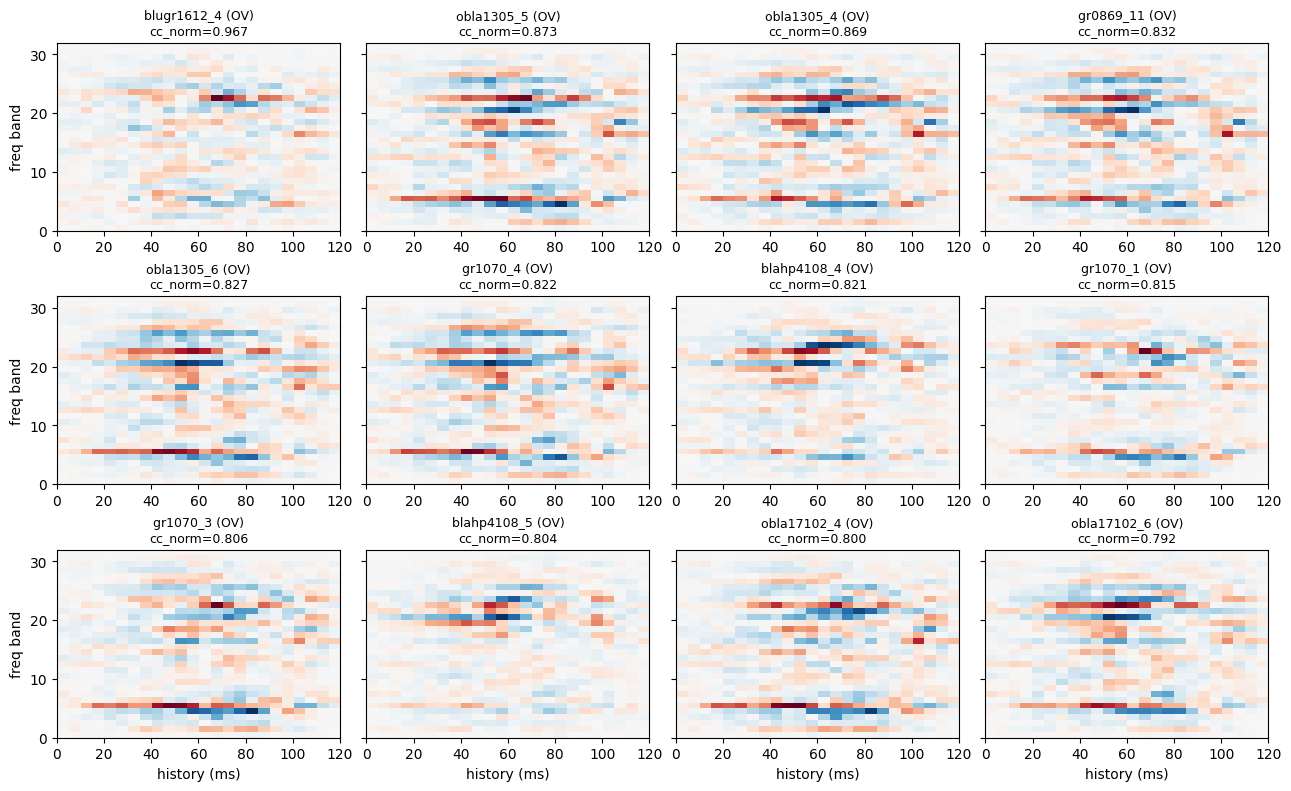
5. STRF gradmaps for the best-predicted cells
model.STRF_gradmap() returns a (N, 1, F, T) tensor — for each output neuron, the gradient \(\partial \mathcal{L}_n / \partial \mathbf{x}_0\) of the negative last-timestep activity with respect to a null (all-zero) spectrogram. Under this sign convention positive entries are inhibitory features — adding mass there would decrease the neuron’s response (see `README_gradmap_strf.md <../md/README_gradmap_strf.md>`__ §4 for the full derivation). To get the more intuitive
excitatory-as-positive plot — red = features the cell prefers — we plot \(-\mathbf{g}_n\), i.e. negate the returned gradmaps before passing them to plot_strf_grid.
This is the closest thing a nonlinear model can give you to a classical reverse-correlation STRF, and it’s the right diagnostic for asking “did the network learn something biologically sensible?” — particularly when the model has no explicit STRF layer.
We pick the 12 best-predicted OV cells (highest test cc_norm). Time runs left to right in units of milliseconds of history. Frequency runs bottom to top (low → high band). Diverging colormap RdBu_r with per-cell symmetric scale so the spatial structure is easy to read across cells of varying gradient magnitude.
[7]:
model.eval()
gradmaps = model.STRF_gradmap() # (N, 1, F, T)
gradmaps = gradmaps.squeeze(1).detach().cpu().numpy() # (N, F, T)
print(f"gradmaps shape: {gradmaps.shape}")
K = 12
test_arr = test_cc_norm.numpy()
order = np.argsort(np.where(np.isnan(test_arr), -np.inf, test_arr))[::-1]
top_idx = order[:K]
print(f"top {K} cells, cc_norm range: "
f"{test_arr[top_idx[0]]:.3f} ... {test_arr[top_idx[-1]]:.3f}")
# Negate so that red (positive) = excitatory under RdBu_r — see the
# markdown above and README_gradmap_strf.md §4 for the sign convention.
titles = [f"{ds.nrn_meta[n]['cell_id'][:14]} ({ds.nrn_meta[n]['area']})\n"
f"cc_norm={test_arr[n]:.3f}"
for n in top_idx]
plot_strf_grid(
-gradmaps[top_idx], titles=titles, dt_ms=ds.dt, ncols=4,
figsize=(4 * 3.2, 3 * 2.6),
)
plt.show()
gradmaps shape: (59, 32, 24)
top 12 cells, cc_norm range: 0.967 ... 0.792
What’s next
Scale up to the full AA2 population. Drop
areas=andstimuli=from the dataset constructor to fit the full 494 cells × 117 stims. Each epoch becomes ~80 s on a single GPU rather than a few seconds, but the gradmap pipeline is identical. Useful for comparing receptive-field structure across MLd / Field L / OV / CM at the population level.Sustained-loss gradmaps. The current
STRF_gradmapuses the last-timestep activity as the loss target — a Spike-Triggered- Average view. A complementary diagnostic is the gradient of the time-averaged activity, which highlights features that drive sustained responses rather than transient ones.Cross-model comparison. Run the same gradmap extraction on a Linear / LinearNonlinear model fit to the same split, and overlay the explicit STRF kernel against the gradient map. They should agree closely on the L/LN models, and the difference between ConvNet2D’s gradmap and an LN’s STRF is exactly the nonlinear contribution.